Introduction
LLM Experimentation powered by rapida.ai
Rapida’s experimentation playground where you can interact with multiple Large Language Models (LLMs) at same time and perform comparisons based on the LLM response, and keep track of metrics such as costs and latency of experiments and provide human feedback.
Use Cases
The experimets are created within your organization for given project any project member that have access can utilize the functionalities and continue the collabration on given experiments.
- The LLM Playground can be used by your teams for a big set of use cases
- Easily test existing use cases and prompts with new models
- Compare new use cases across different models and collect insights on quality, performance and costs
- Experiment with changing hyperparameters of models
- Experiment with new and updated prompts to get a quick sense of the performance of a model
- Provide feedback on responses to create datasets for future fine-tuning
Chat and Text Experimentation
RapidaAi support both experimentations either completion for a single prompt or a complete conversational dialog. For most of the LLM models completion for a single prompt is taken care by completion endpoint, whereas the /chat/completions provides the responses for a given dialog and requires the input in a specific format corresponding to the message history.
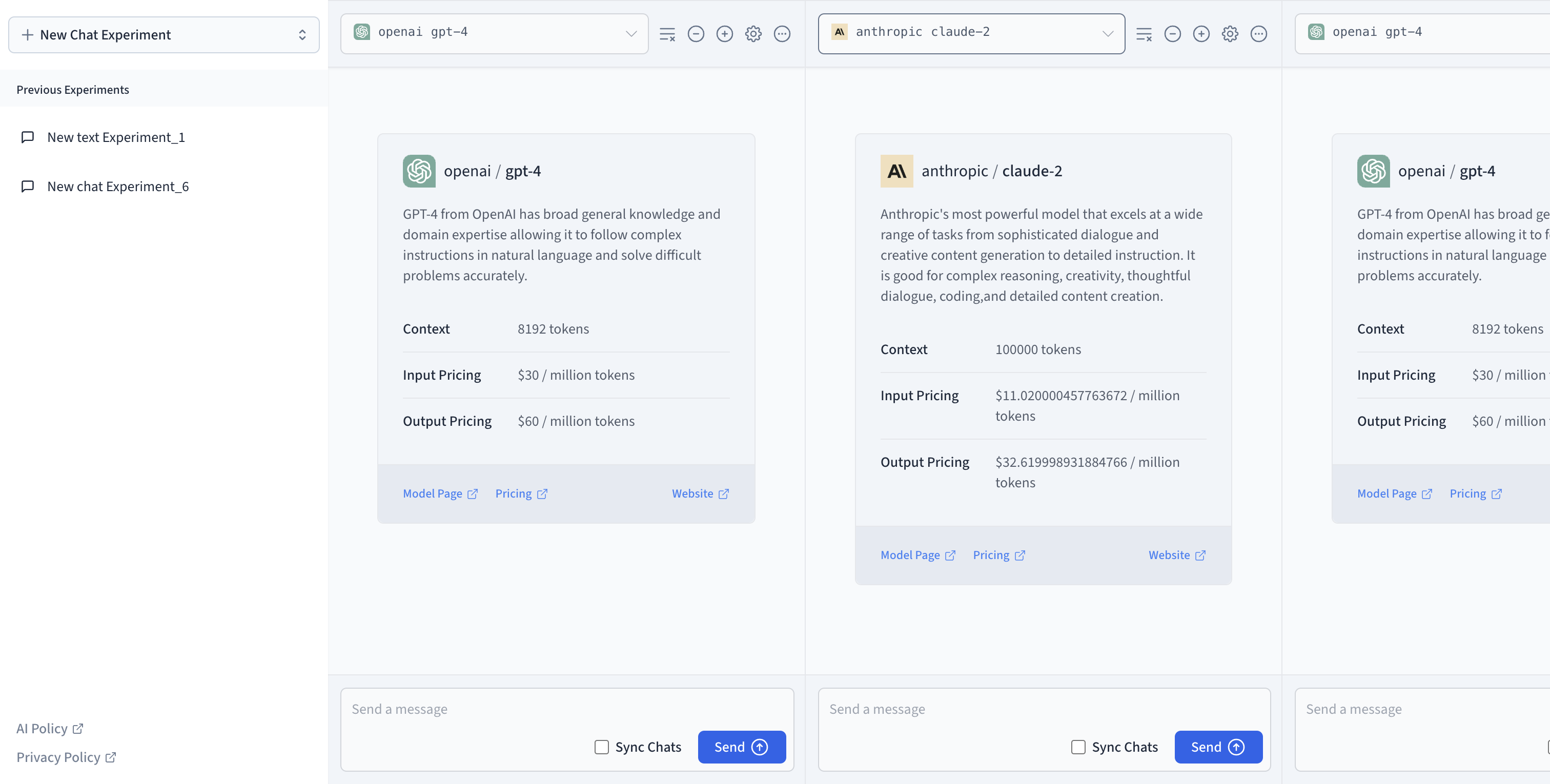
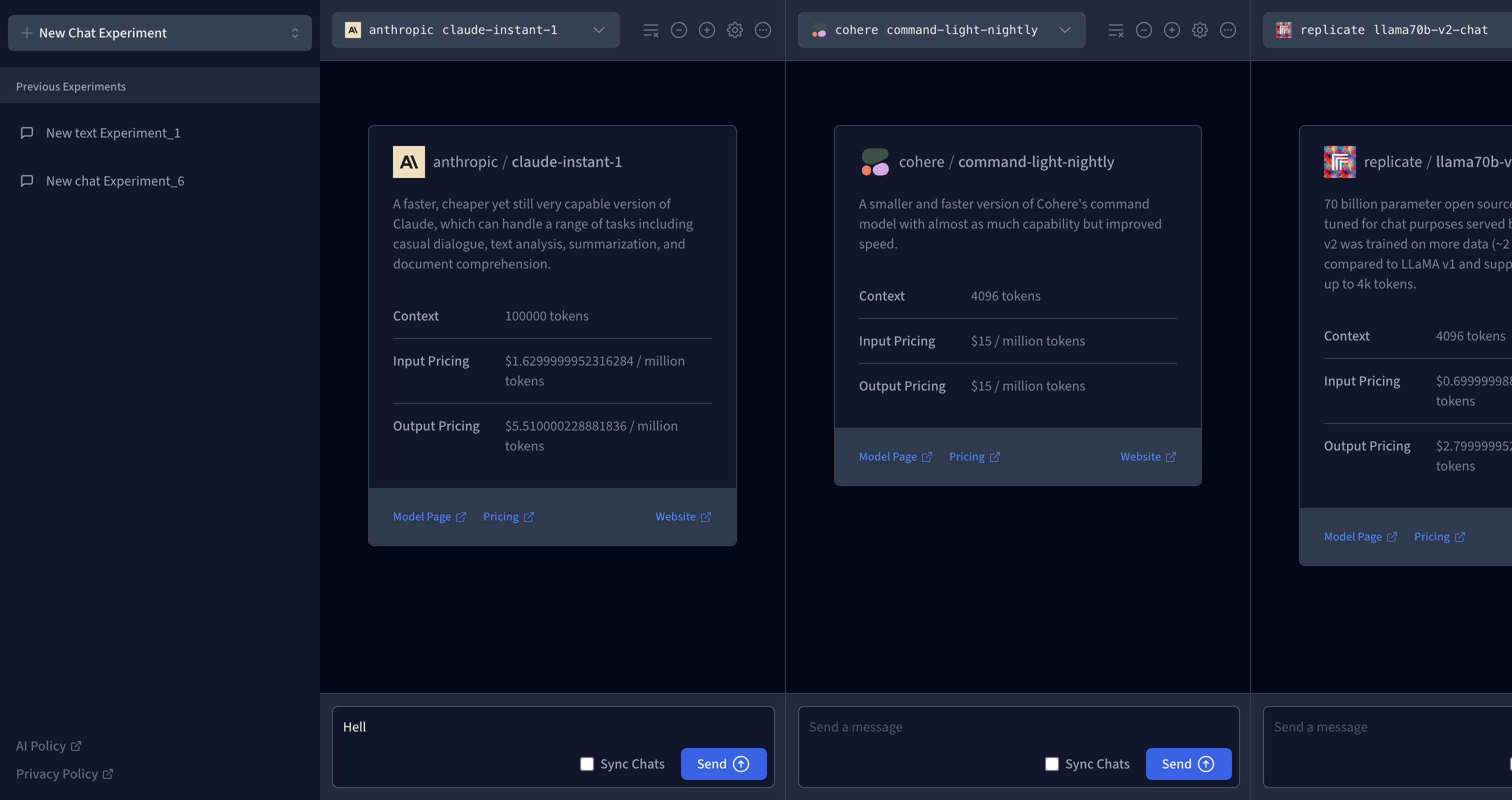
Chat Experiment
Prompt Text Experiment
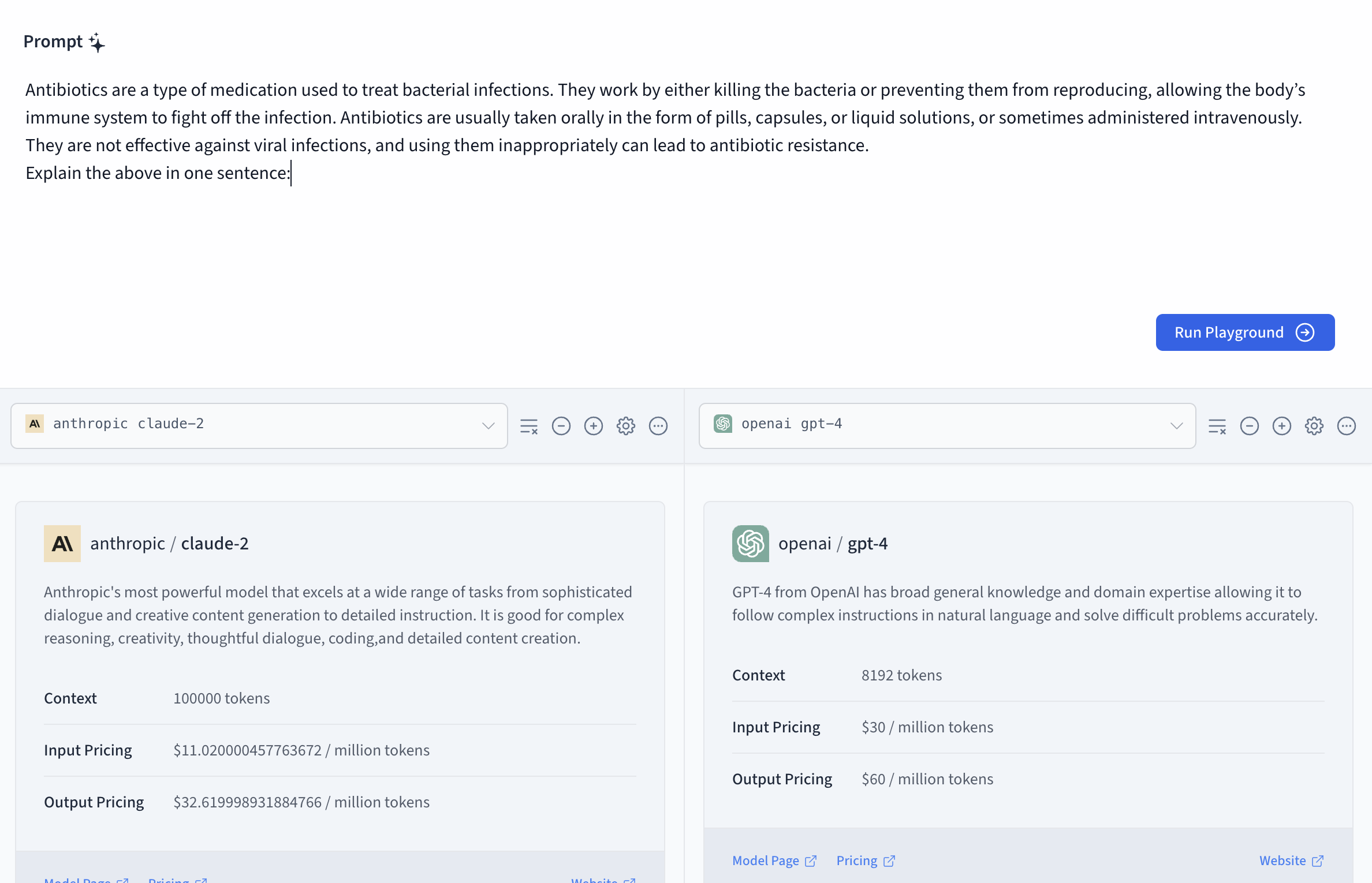
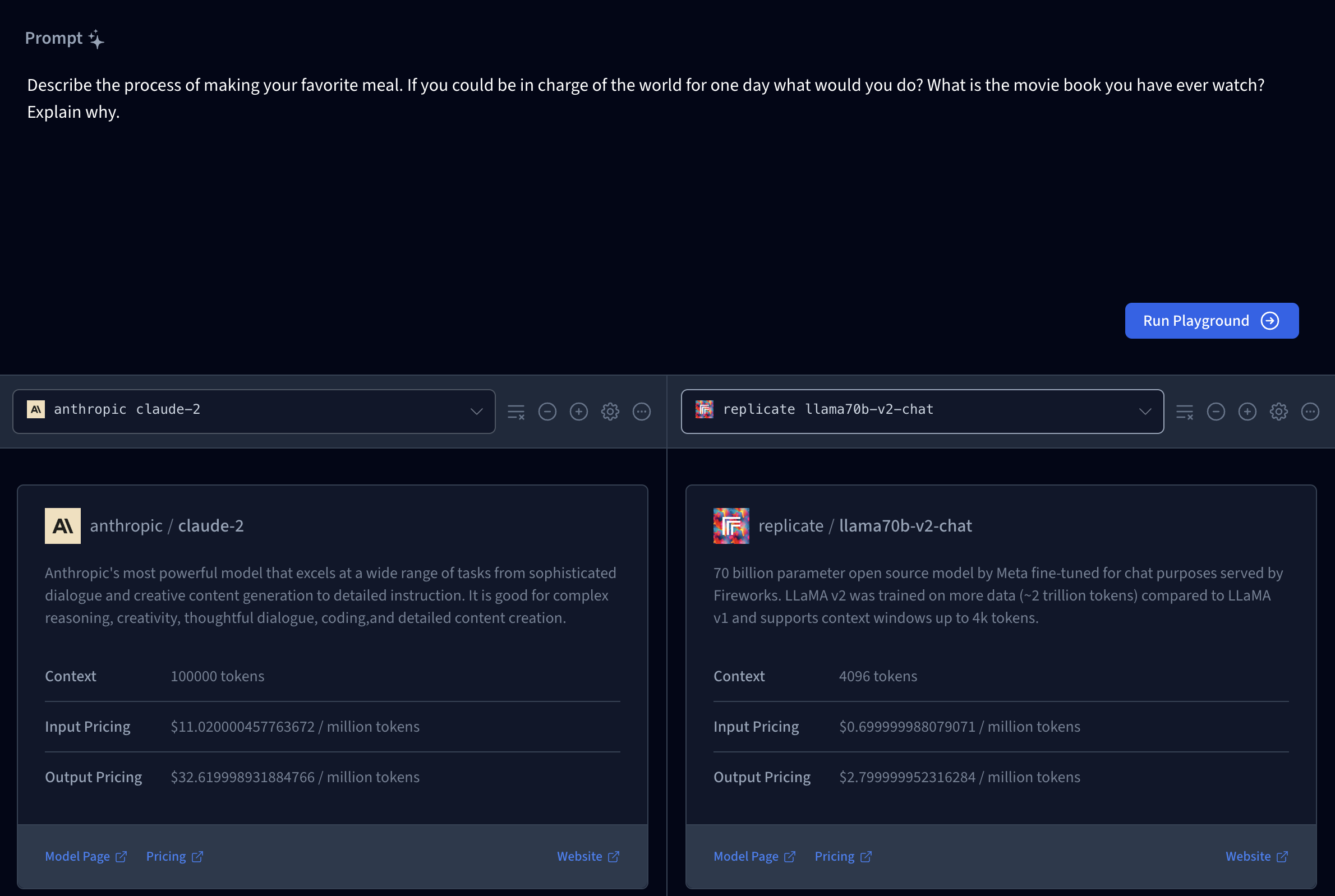
Model Selections
For your model, you can select a model by clicking on the Model selection dropdown, and you will be able to access the activated models available in the playground. To get a better response from the model, the playground offers a unique feature that helps configure the model by clicking on the gear icon. Some of these parameters include Number of words, Frequency Penalty, Temperature, Top K and Top P.
To input your prompts, you use the prompt field within the block; type in your prompt and press the send button. You can sync chats in the playground to easily test the same prompt across different model configurations.